
Understanding Deep Learning and Its Core Components Intuitively

Deep learning has become an integral topic in many areas of our lives, from medicine to physics, from large language models to autonomous vehicles. This article provides intuitive explanations of deep learning and its fundamental components. Learning these concepts, which may seem intimidating at first glance, in a clear and understandable way is especially important during project development phases.
What is Deep Learning?
Before defining deep learning, it will be helpful to define artificial intelligence (AI) and machine learning (ML) to make the topic easier to understand. This is because deep learning is a subfield of machine learning, and machine learning is a subfield of artificial intelligence.
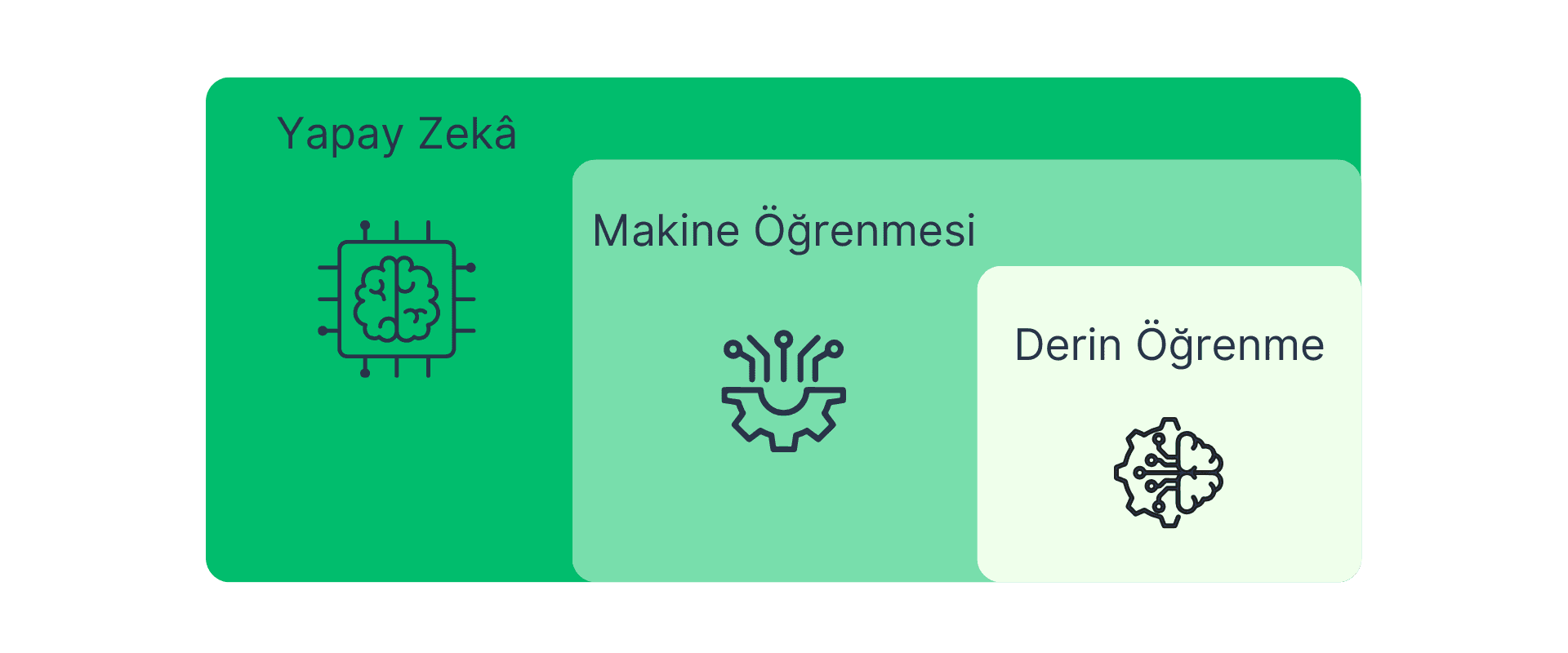
- Artificial Intelligence (AI): Systems that perform functions like decision-making, learning, and problem-solving by imitating human behavior.
- Machine Learning (ML): A subfield of AI, ML uses statistical algorithms to make decisions by learning from datasets.
- Deep Learning (DL): A subfield of ML, DL performs the learning process through artificial neural networks, allowing the extraction of more complex features from data. Unlike other machine learning methods, deep learning can learn complex structures in data more abstractly and effectively with less feature engineering intervention.
Artificial neural networks have become one of the most commonly used technologies today, appearing in many areas of our lives. They are most commonly developed with the Python programming language; the PyTorch, TensorFlow, and Keras libraries are among the most widely used tools. Deep learning algorithms are becoming more powerful and efficient with each passing day. Behind this development are advancements in both software and hardware—particularly in GPUs and cloud technologies—and the increase in the amount of data, which are critical parameters in the widespread adoption of deep learning.
Compared to traditional machine learning methods, models require less human intervention, as they often work directly on raw data by learning from it. Because of this feature, deep learning models are sometimes referred to as "black boxes." In recent years, the rapid increase in the amount of data has greatly contributed to making deep learning models even more effective. In your projects, you can train your own models, or you can take advantage of pre-trained models that are accessible and trained on large datasets.
Understanding the Learning Process in Deep Learning
To make the "learning" process in deep learning more understandable, let’s say you are working on a music genre classification project, and your goal is for the model to correctly classify new music tracks. When humans listen to a music track, they refer to similar tracks they've heard before and analyze the texture of the piece they are currently listening to in order to understand its genre. For example, when a punk rock track is played, we can easily infer its genre by referencing similar tracks we've heard before and the other characteristics of the genre. Deep learning models work similarly by using artificial neural networks. The more music tracks you present to your model, the more accurate the classifications will be. The term “deep” refers to the multi-layered structure of artificial neural networks and the abundance of hidden layers. The following section provides intuitive explanations of the layers and other basic components.
Key Components of Deep Learning
Understanding the fundamentals of artificial neural networks used in this highly dynamic field plays a critical role in developing the right model and making applications efficient. Artificial neural networks are AI models that consist of multiple perceptrons arranged in layers, processing data to produce results. Each layer performs a specific function, and as the data passes through the network, more complex features are learned. These networks can be used for classification, regression, feature extraction, and many other problems.
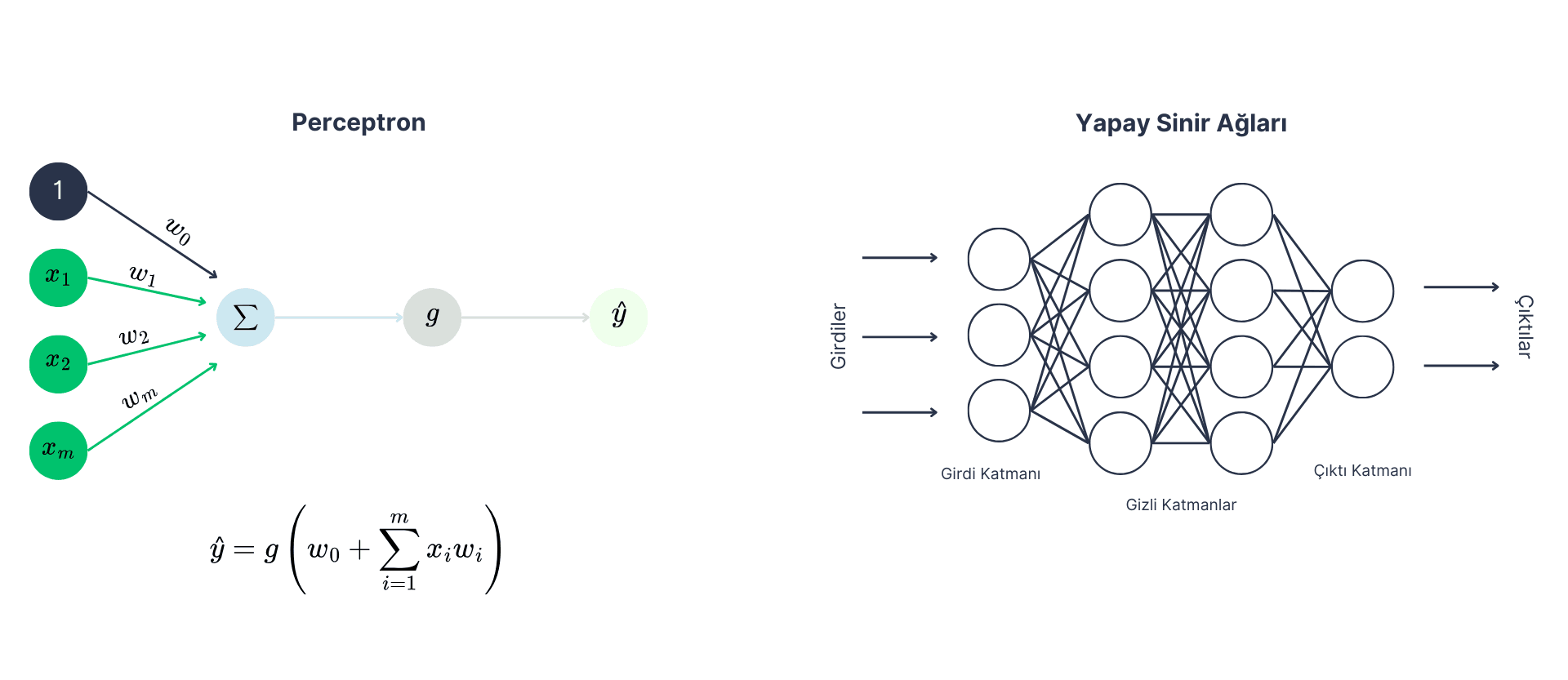
- Perceptron: The basic building block of artificial neural networks, which can be thought of as a single neuron. Each perceptron processes input data and performs a calculation on the data by multiplying the input data with weights and adding a bias term. The resulting value is passed through an activation function, and an output is produced. This output can then be used as input for the next layer. For example, in the music genre classification project, each perceptron helps classify a music track by assigning weights to different features of the track (e.g., tempo, tone).
- Layer: In neural networks, a layer is a structure formed by multiple perceptrons coming together. Each layer processes input data and generates outputs to pass on to the next layer. Typically, there are three main types of layers: input layer, hidden layers, and output layer. In the music genre classification example, the input layer takes the basic features of the music track, while the hidden layers transform these features into meaningful categories through deeper learning.
- Weights and Bias (wm and w0): In neural networks, each perceptron processes input data using certain weights and a bias term. Weights determine the importance of the input data for the model, while the bias term is used to make the model's predictions more flexible. Weights and bias come together to form the perceptrons, laying the foundation for the learning process in neural networks.
- Activation Function (g): A mathematical function that determines the output of each neuron in the neural network. It is generally used to provide the non-linear structure of the model, as real-world data often contains non-linear relationships. Common activation functions include sigmoid, ReLU, and hyperbolic tangent. These functions enable the network to learn more complex, non-linear data.
- Loss Function: A function that measures the difference between the predicted values and the actual values. The goal is to minimize this difference, i.e., to minimize the error rate of the model. During the training process, the model calculates how closely its predicted music genres match the actual genres and tries to minimize this difference. The loss function becomes a criterion to optimize in order to increase the model's accuracy.
- Optimization Algorithms: Gradient descent is an optimization algorithm used to minimize the loss function. It works by updating the weights to reach the minimum value of the loss function by calculating its derivative. The goal of this algorithm is to minimize the prediction errors of the model. Gradient descent can be applied in different forms: batch gradient descent, stochastic gradient descent, and mini-batch gradient descent are some examples.
- Regularization Techniques: Overfitting occurs when the model fits too well to the training data but performs poorly when generalized to real-world data. Techniques such as dropout and early stopping are used in deep learning models to prevent this problem. In music genre classification, it's important that the model not only fits the training data but also adapts to real-world music, which is why these techniques are crucial for improving the overall success of the model.
Many models operate based on these concepts, and deep learning models are developed by referencing the human brain in this way. A few years ago, it was predicted that the costs of current applications would be higher, but application costs have dropped much lower than expected. Investments and advancements in GPUs, combined with the increasing data load, indicate that models based on these fundamental concepts may become even more widespread in the near future.



